面向海外高校升学信息
检索增强生成系统的设计与实现
Design and Implementation of a RAG System
for Overseas University Admission Information
研究背景与意义
留学申请是高风险、强时效的决策过程。学生面临的不是信息不够多,而是难以核实、难以对比、难以追溯。
- · 海外院校官网信息分散,学生在多个标签间反复切换
- · 通用大模型回答"看起来对",但无法核查、无法溯源
- · 招生政策频繁更新,模型训练数据已过时
- · 中介信息存在商业偏向,难以做客观对比
通用 LLM 的两大根本局限
知识截止 · Training Cutoff
模型训练数据存在截止时间,而留学政策、申请截止日期、专业要求频繁变动。模型无法获取训练截止后的任何新信息。
幻觉 · Hallucination
模型以高置信度输出与事实不符的内容。在留学这类高风险决策场景中,看起来合理但错误的答案,远比"不知道"危险。
检索增强生成 RAG
RAG 由 Lewis 等人于 2020 年提出。生成回答前先从外部知识库检索相关文档片段,作为上下文传入 LLM,缓解知识截止与幻觉问题,无需对模型参数微调。
混合检索 + 知识图谱
基于词频统计的概率检索模型,对专有名词、缩写、数字(如 GMAT、IELTS 7.0)有精确匹配优势,弥补向量检索语义近似的不足。
按排名而非分数融合,自然消除两路检索分数量纲差异,工程实践中应用广泛。
以三元组 ⟨主体, 谓词, 客体⟩ 存储实体关系。GraphRAG 将跨文档推理转化为图路径遍历,对"跨校比较 / 多跳推理"类查询更可解释、更易追溯。
爬虫 · 前后端技术栈
海外院校官网普遍采用 React / Vue 等 SPA 框架,传统爬虫拿到的是空壳 HTML。无头浏览器先执行 JS 渲染,再抽取正文并输出结构化 Markdown。
采用现代 Python 异步 Web 框架,提供 RESTful 接口与流式响应能力,承载检索、问答、管理等业务逻辑。
基于 React 组件化开发,Next.js 提供路由与服务端渲染能力。Node.js 作为运行环境,前端通过 SSE 实时接收回答流。
PostgreSQL 存储用户与会话;Neo4j 同时承载文档向量、全文索引与实体图谱,简化跨索引一致性管理。
系统总体架构
院校官网数据采集
海外院校官网约 90% 基于 SPA 框架动态渲染,传统 HTTP 爬虫只能拿到空壳 HTML。
解决方案 · Firecrawl
- · 底层无头浏览器,完整执行 JS 渲染
- · 自动清洗导航、页脚、广告等非主体内容
- · 输出 LLM 友好的结构化 Markdown
- · 支持单页精准抓取 + 站点级联爬取
混合检索管道
核心:混合检索器
① 意图识别 — 调用 NER 模型抽取查询中的学校实体(如"Imperial"),同时检测是否包含对比关键词("对比"、"哪个更好"),判断查询模式(单校/多校/开放)。
② 并行双路查询 — 在 Neo4j 中同时执行向量检索(db.index.vector.queryNodes)与 BM25 全文检索(db.index.fulltext.queryNodes),两路异步并行减少串行延迟。特殊字符转义防止 Lucene 注入。
③ RRF 融合 — 将两路结果按排名融合(k=60 超参来自工程实践),自动去重、合并候选集,避免单一检索策略的局限性。
④ 跨校配额 — 若检测到多校对比查询,对融合结果按学校分桶(bucket),确保每校至少分配 2 个候选文档,避免单校垄断 Top-K。
⑤ 精排 — 调用 BGE Cross-Encoder 重排序候选集,计算 Query 与每个候选的语义相关度得分,取 Top-5 传入 LLM 生成最终答案。
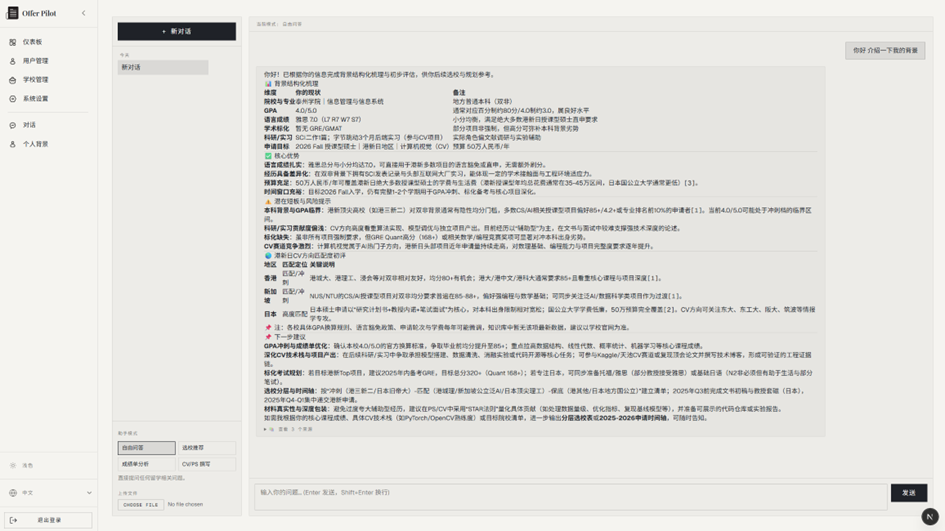
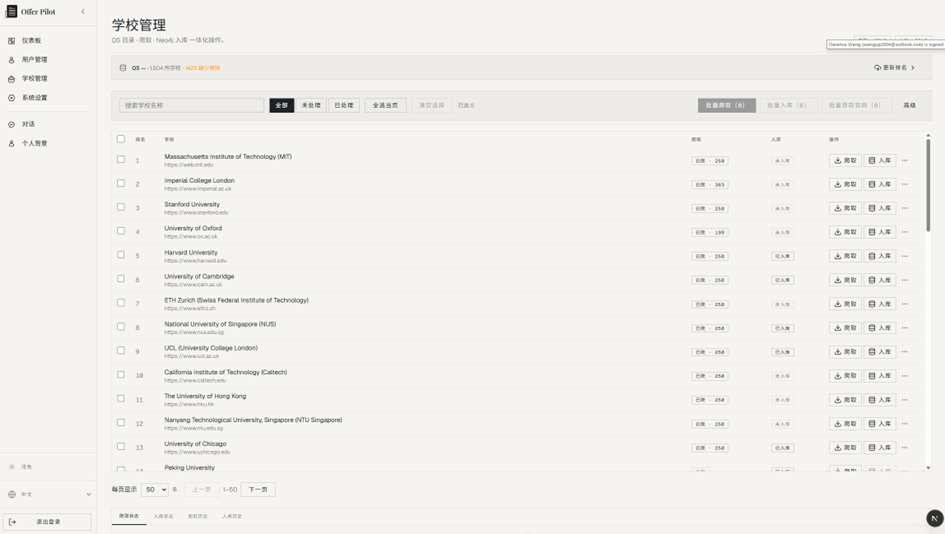
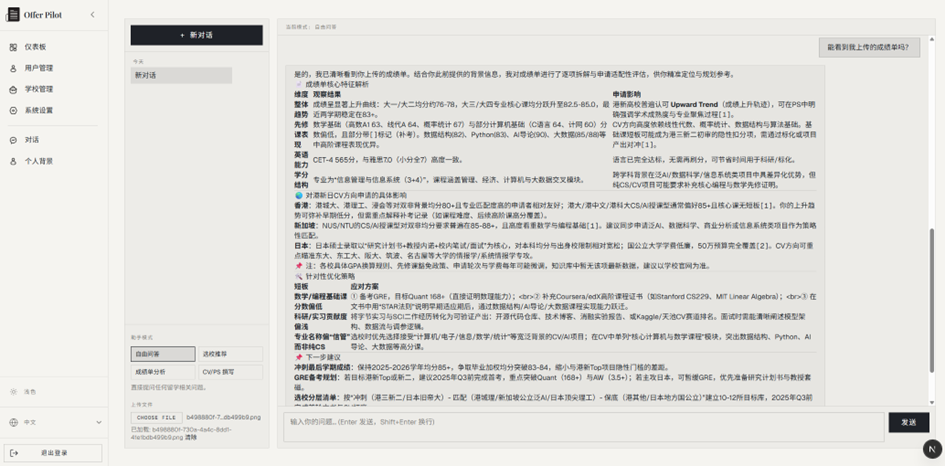
系统界面展示
完整实现从用户登录、个人背景采集、对话问答,到后台学校与用户管理的全流程功能。
关键实验数据
在 60 道领域专项问答对上,对比通用大模型基线 DeepSeek-V3 与本系统的端到端效果。
核心结论
本研究围绕"让大模型在留学场景下回答更可信、更可查、更贴合个体",完成了一套可运行的端到端系统。
引入检索后,回答均来自真实文档片段,并附引文链接,显著优于直接调用通用大模型。
通过爬虫定期采集官网,知识库可持续更新,避免大模型训练截止带来的过时问题。
从前端登录到后端检索、从普通用户到管理员的完整业务闭环,验证了方案的工程可行性。
主要创新点
针对海外院校官网普遍采用动态渲染、传统爬虫失效的问题,采用无头浏览器方案获取真实正文,并清洗为 LLM 友好的结构化 Markdown。
将文档检索与院校—项目—要求三元组结合,回答既能精确引用原文,又能沿图谱关系完成"跨学校 / 多条件"类比较,答案可溯源。
通过个人背景向导收集学生画像并注入对话上下文,使系统输出"针对你"的建议,区别于通用问答机器人。
谢谢各位老师
感谢指导教师蔡程飞老师在选题、技术路线与论文写作上的悉心指导; 感谢答辩委员会各位老师在百忙之中评阅本论文; 感谢同学与家人一路以来的支持与陪伴。
恳请各位老师批评指正